

 困っている人
困っている人
- Pandasでグループ毎でデータを集計する方法を知りたい
- 統計量(平均など)を算出する方法を知りたい
- groupby関数の具体的な使い方を教えてほしい
- グループ毎のデータの集計方法(groupby)が分かる
- 統計量(平均・最小・最大・標準偏差など)の算出方法が分かる
- groupby関数の具体的な使い方が分かる
Pandasのgroupbyの使い方

Pandasの「groupby」は、同じグループのデータをまとめて、任意の関数(合計・平均など)を実行したい時に使用します。
例えば、”商品毎”や”月別”の販売数を集計して売上の要因を分析するなど、データ分析でよく使うテクニックなので、ぜひ参考にしてください。
Pandasのgroupbyの仕組み
groupby関数の仕組みを図で説明します。まず、DataFrameのバラバラのデータ(りんご・ぶどう)を「グループ化」します。そして、任意の関数(以下の例はSUM)を実行し、適用した結果をDataFrameへ反映します。
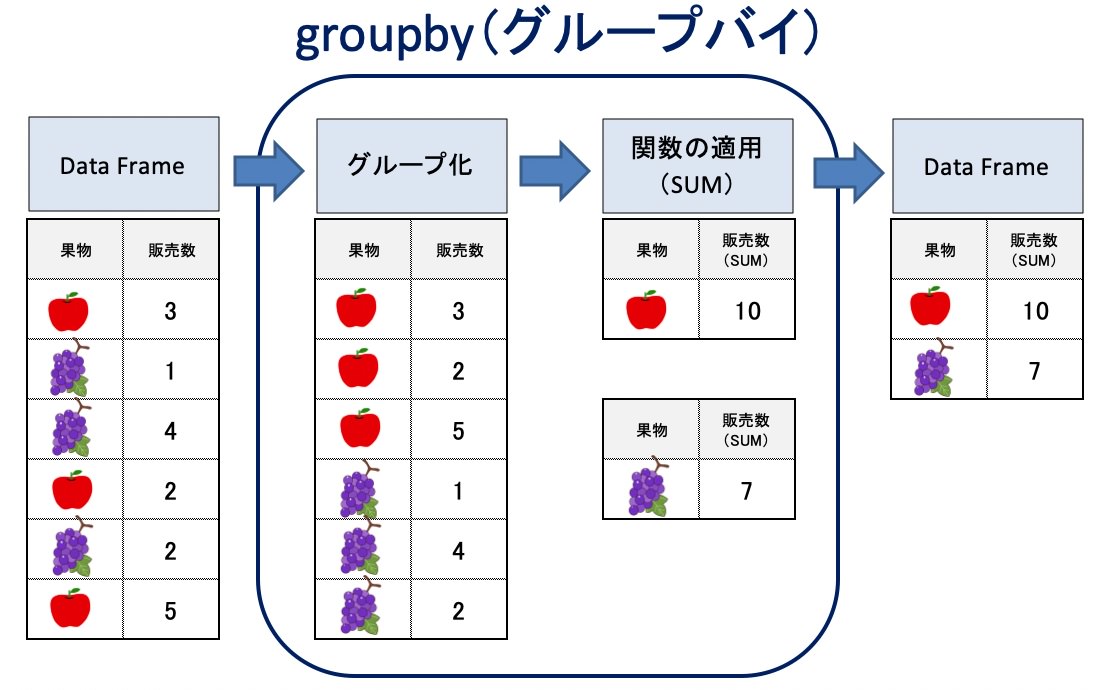
上記の例では合計(SUM)で説明しましたが、平均・標準偏差・最小値・最大値、あるいは自分で作成した関数を適用することも可能です。
Pandasのgroupbyの使い方
今回紹介するgroupbyの使い方一覧です。No.1〜No.4までを順に説明していきます。
| No. | 基本形 | 説明 |
| 1 | df.groupby(“商品名”).count()[“日付”] | 商品名ごとに日付の個数を算出 |
| 2 | df.groupby(“商品名”).sum()[‘販売数量’] | 商品名ごとに販売数量を合計 |
| 3 | df.groupby(‘商品名’).mean() | 商品名ごとの平均を算出 |
| 4 | df.groupby(‘商品名’).describe()[‘販売数量’] | 商品名ごとの基本統計量を算出 |
Pandasのgroupbyのサンプルデータ
この記事では以下のサンプルデータを使います。よろしければ、ダウンロードしてご利用ください。
[st-mybox title=”” fontawesome=”” color=”#757575″ bordercolor=”#7ca1b7″ bgcolor=”#ffffff” borderwidth=”2″ borderradius=”2″ titleweight=”bold” fontsize=”” myclass=”st-mybox-class” margin=”25px 0 25px 0″]
- サンプルデータ(’ fruits‘)
[/st-mybox]
また、GoogleColabへのサンプルデータ(Excelファイル)の読み込み方法については、以下の記事を参考にしてください。
[st-card id=180 label=”” name=”” bgcolor=”” color=”” fontawesome=”” readmore=”on”]
Pandas groupbyでデータの個数を算出

それでは、「groupby」によるデータの個数を算出する方法から説明していきます。まずはExcelファイルを読み込んでください。
Excelファイル(fruits_1)の読み込み
Pandasを使ってExcelファイルを読み込みます。インデックス(一番左の列)を見ると、0から364までの365日分のデータであることが分かります。
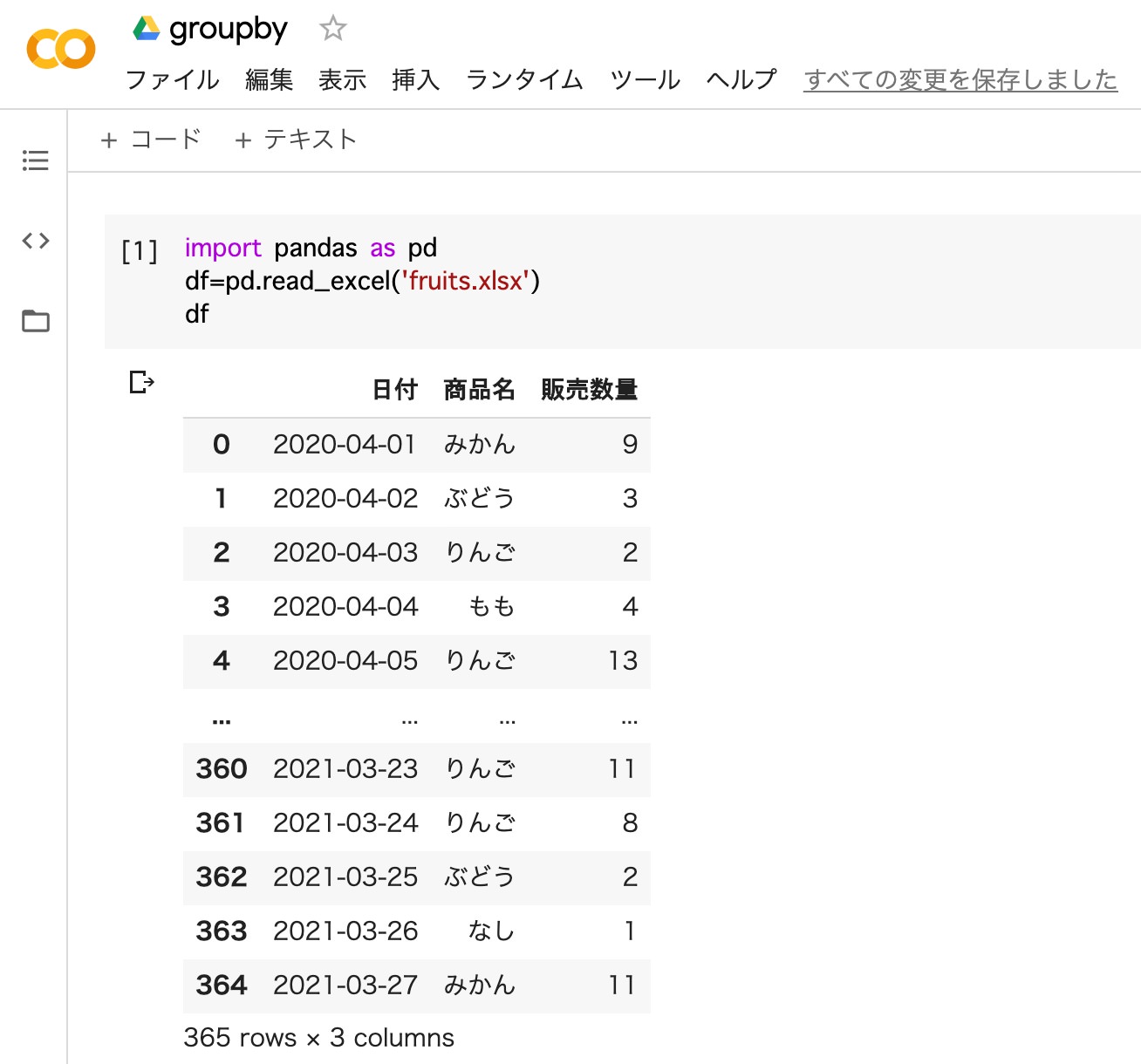
import pandas as pd
df=pd.read_excel('fruits.xlsx')
df
- pandasをインポート
- 変数(df)にExcelファイルから読み込んだデータフレームを代入
- 変数(df)を出力
データの個数を算出(groupby×count)
データの個数を集計する場合は、「groupby」と「count」を組み合わせます。”日付”の列にそれぞれの商品名の販売日数が表示されているのが分かります。
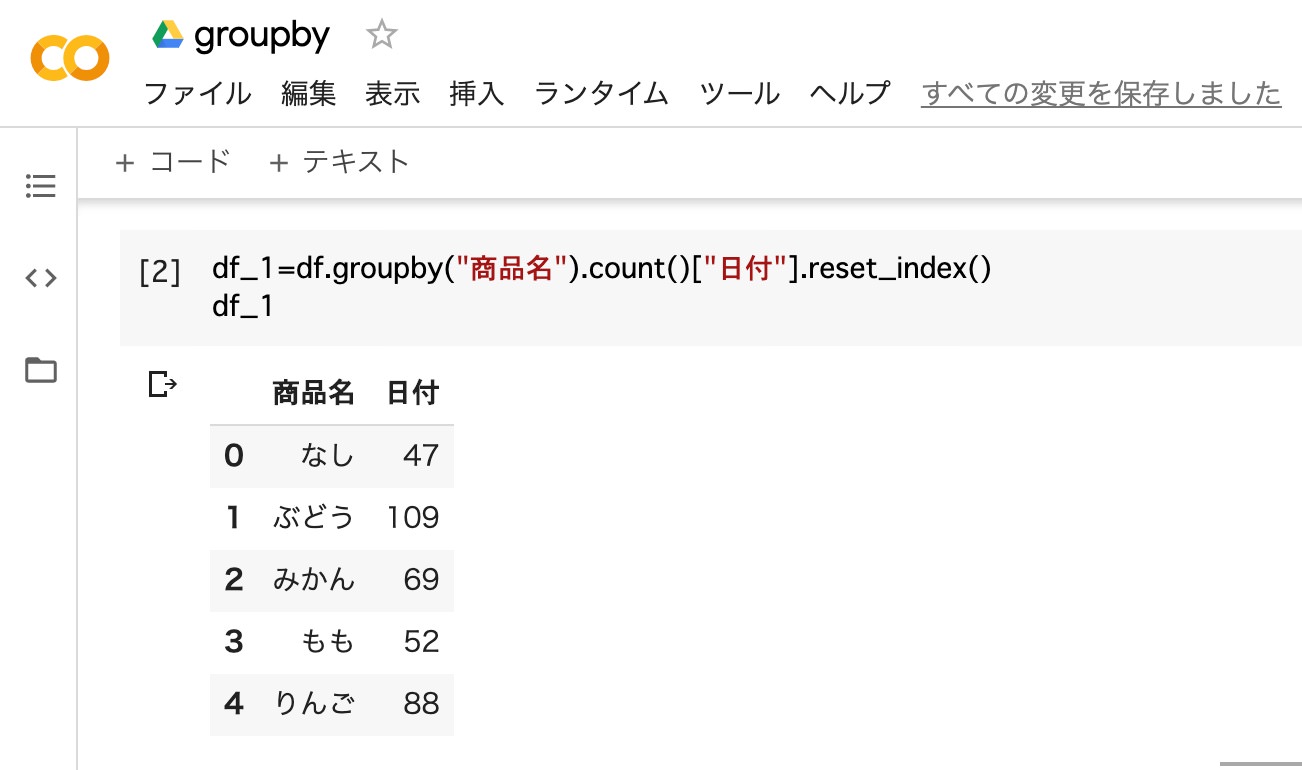
df_1=df.groupby("商品名").count()["日付"].reset_index()
df_1
- 変数(df_1)に、”商品名ごと”で”日付の個数”を集計したデータフレーム を代入
- 変数(df_1)を出力
Pandas groupbyでデータの合計を算出
データの合計を集計する場合は、「groupby」と「sum」を組み合わせます。”販売数量”の列にそれぞれの商品名の販売合計が表示されているのが分かります。
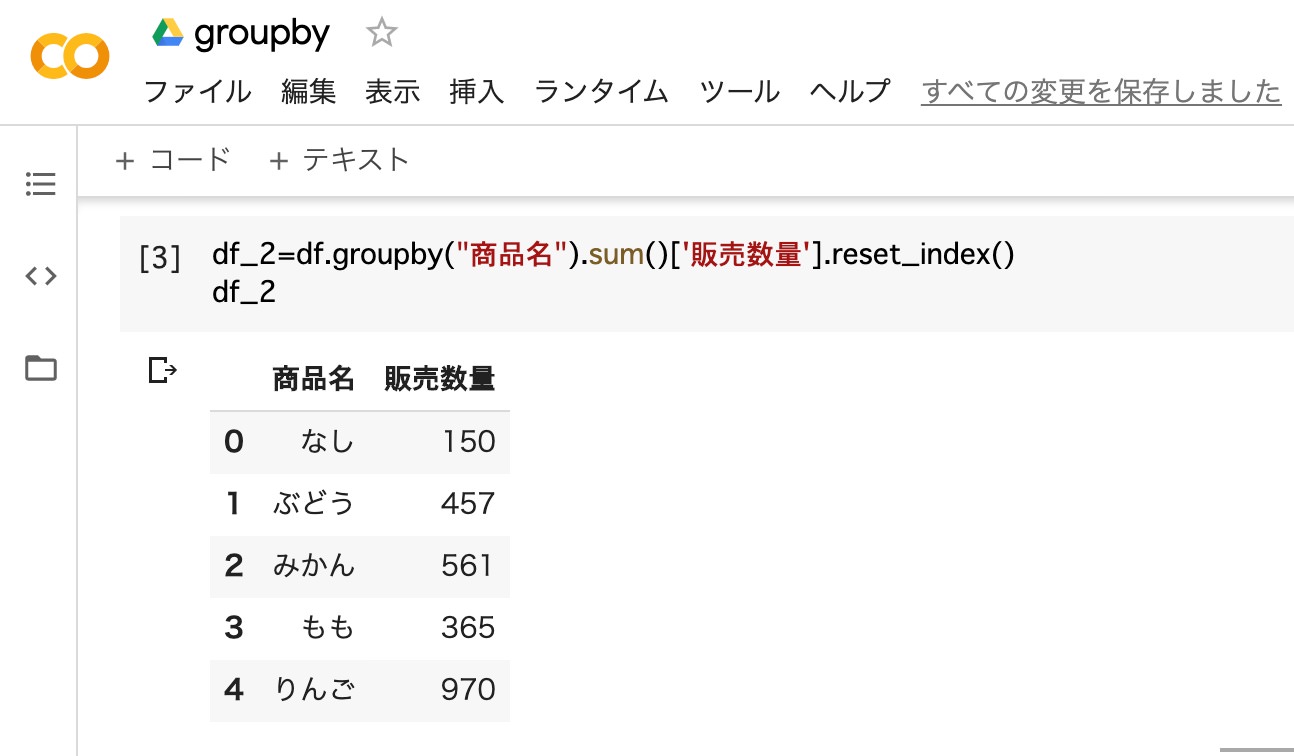
df_2=df.groupby("商品名").sum()['販売数量'].reset_index()
df_2
- 変数(df_2)に、商品名ごとで販売数量を合計したデータフレーム を代入
- 変数(df_2)を出力
Pandas groupbyでデータの合計を算出(月毎)

次に、販売数量を「月毎」で合計する方法について説明します。先ほど説明したとおり「groupby」と「sum」を組み合わせて算出します。売上データの要因分析でよく使うテクニックで覚えておくと便利です。以下の手順で説明します。
[st-mybox title=”” fontawesome=”” color=”#757575″ bordercolor=”#7ca1b7″ bgcolor=”#ffffff” borderwidth=”2″ borderradius=”2″ titleweight=”bold” fontsize=”” myclass=”st-mybox-class” margin=”25px 0 25px 0″]
1.”年月日”から”年月”に変換する
2.”年月”で”販売数量”を合計する
3.”年月”と”商品名”で”販売数量”を合計する
[/st-mybox]
日付データを”年月日”から”年月”に変換する
”年月”で合計するために、まずは日付を”年月日”から”年月”に変換する必要があります。詳しくは、日付を変換する方法をご確認ください。
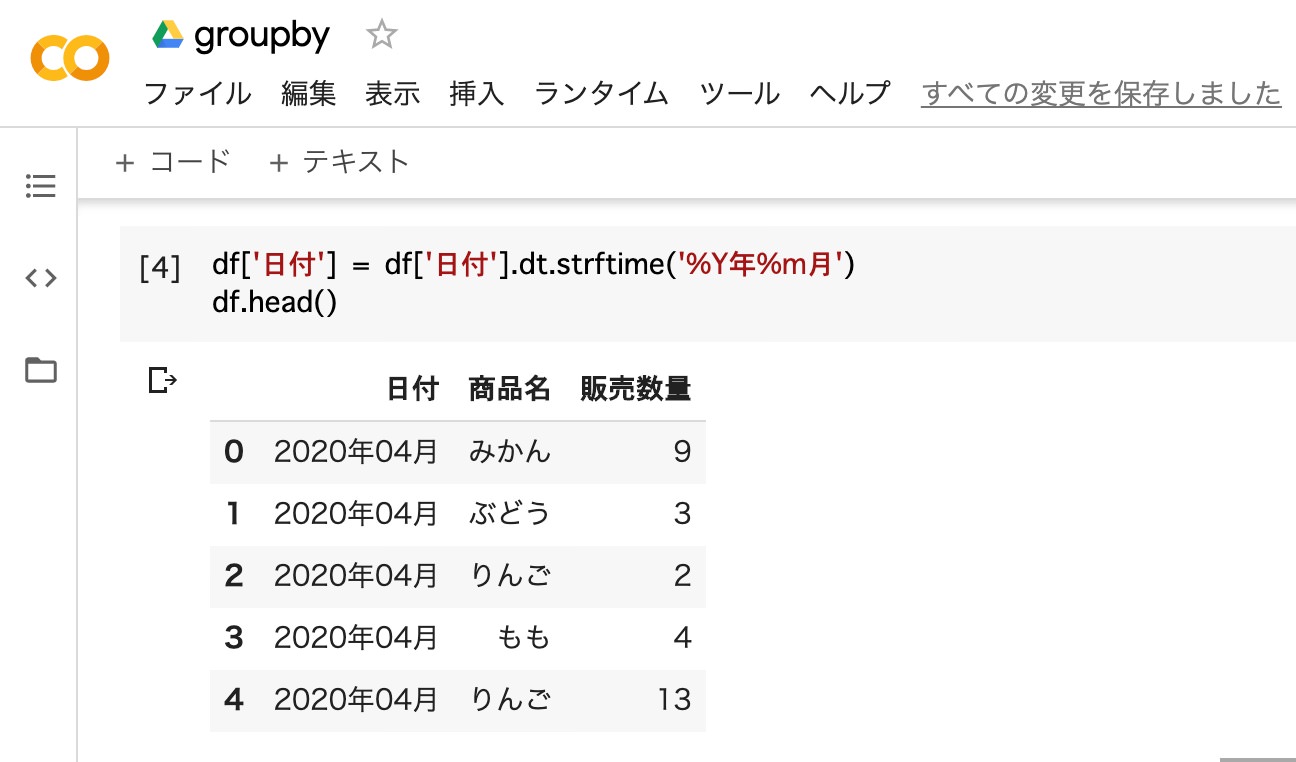
df['日付'] = df['日付'].dt.strftime('%Y年%m月')
df.head()
- 変数(df_1[‘日付’])に、年月日を年月に変換したデータフレーム を代入
- 変数(df)を出力
Pandas groupbyでデータの合計を算出(年月毎)
「groupby」と「sum」を組み合わせて、年月(日付)毎に販売数量を合計します。”販売数量”の列に合計が表示されているのが分かります。
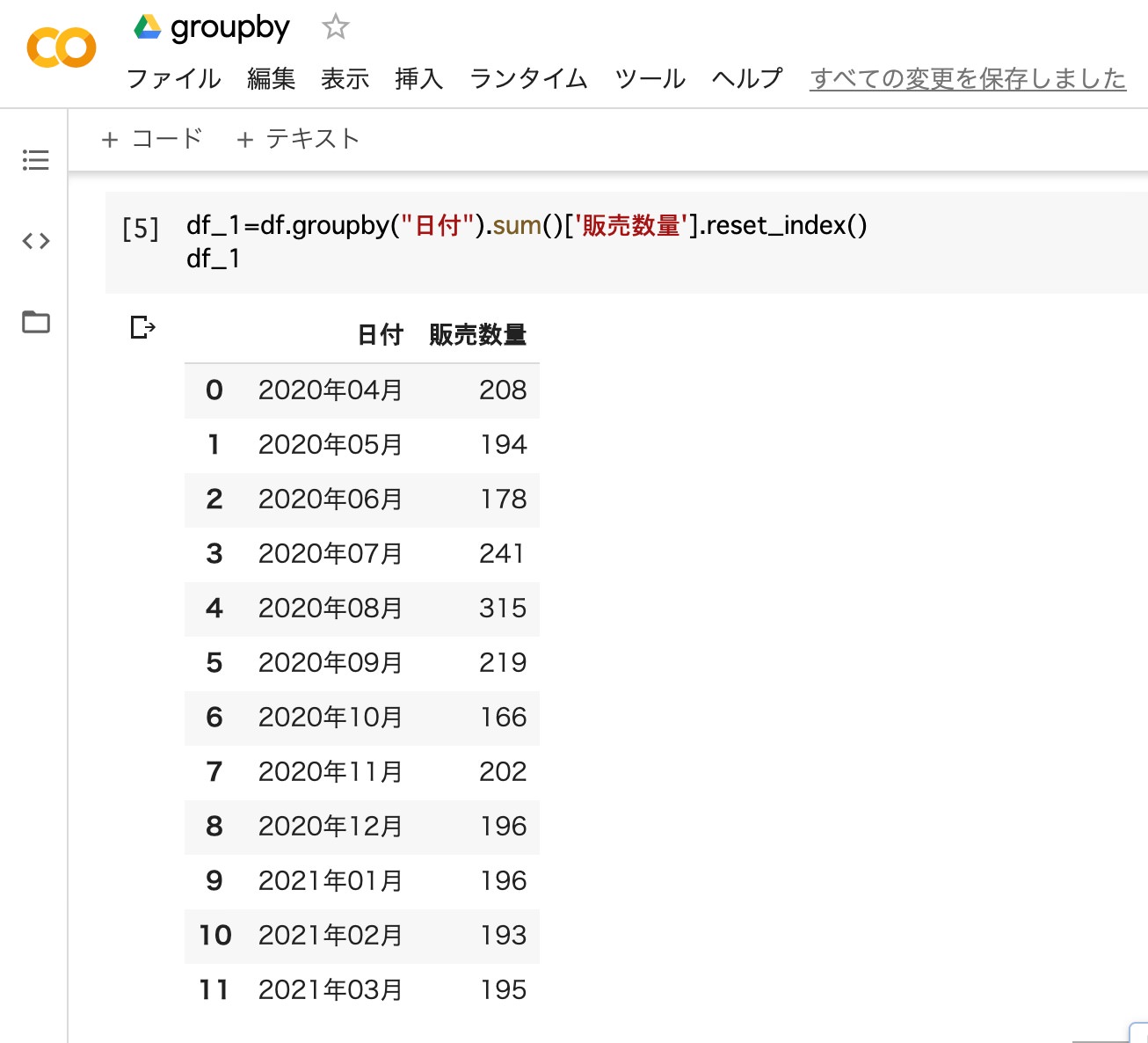
df_1=df.groupby("日付").sum()['販売数量'].reset_index()
df_1
- 変数(df_1)に、日付(年月)毎に販売数量を合計したデータフレームを代入
- 変数(df_1)を出力
Pandas groupbyでデータの合計を算出(年月×商品)
さらに、”年月毎”と”商品毎”で販売数量を合計する方法を説明します。”販売数量”の列に合計が表示されているのが分かります。データが多い(2020年4月〜2021年〜3月)ので、最初の10行だけ出力しています。
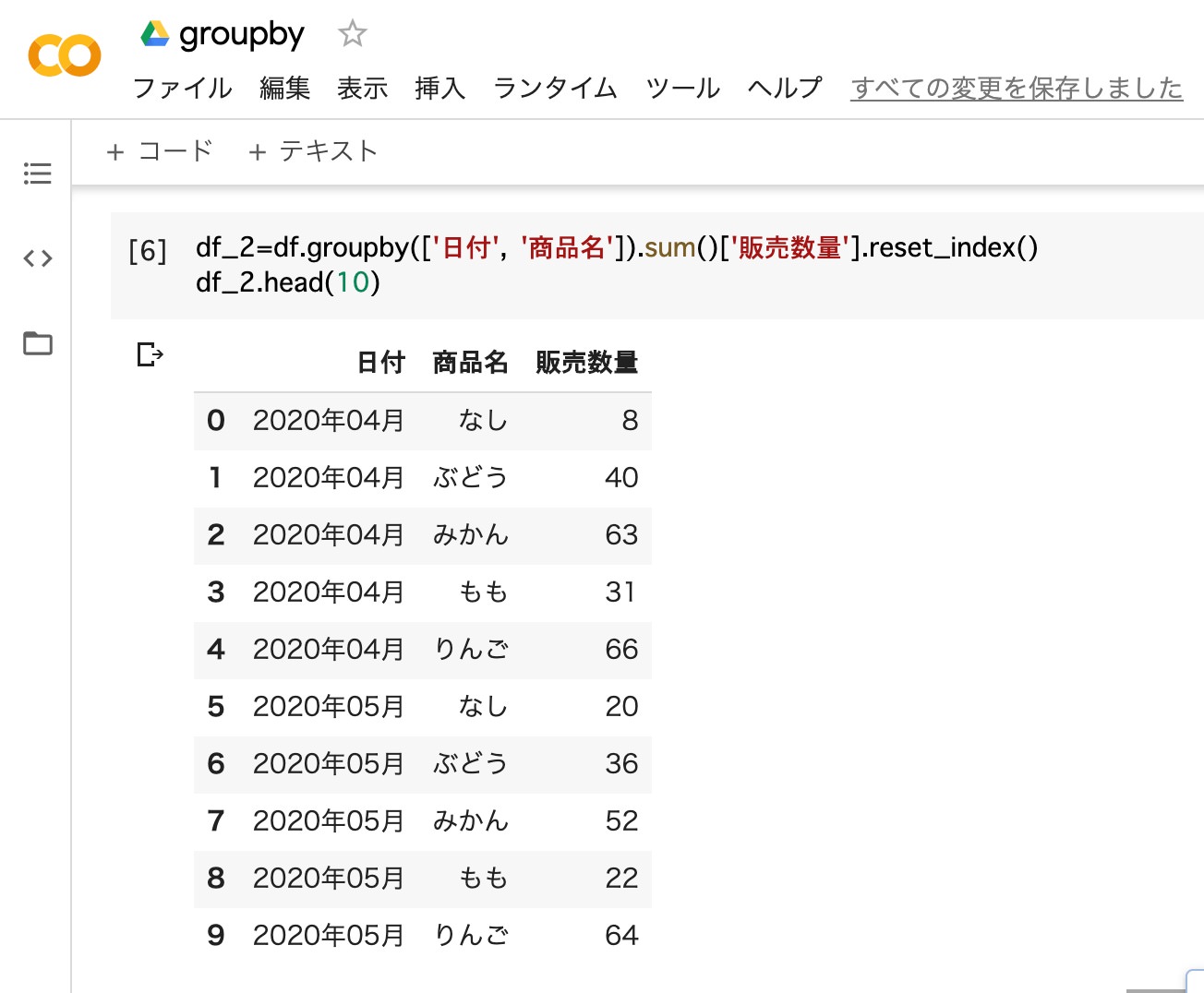
df_2=df.groupby(['日付', '商品名']).sum()['販売数量'].reset_index() df_2.head(10)
- 変数(df_2)に、”日付毎”と”商品名毎”に販売数量を合計したデータフレームを代入
- 変数(df_2)の最初の10行を出力
Pandas groupbyでデータの統計量(平均など)を算出

次に、「groupby」を使った統計量の算出方法について説明します。まずは、平均の算出方法です。
Pandas groupbyでデータの平均を算出(mean)
「groupby」と「mean」を組み合わせると、データの平均を算出します。販売数量の列に、それぞれの商品の平均販売数が表示されているのが分かります。
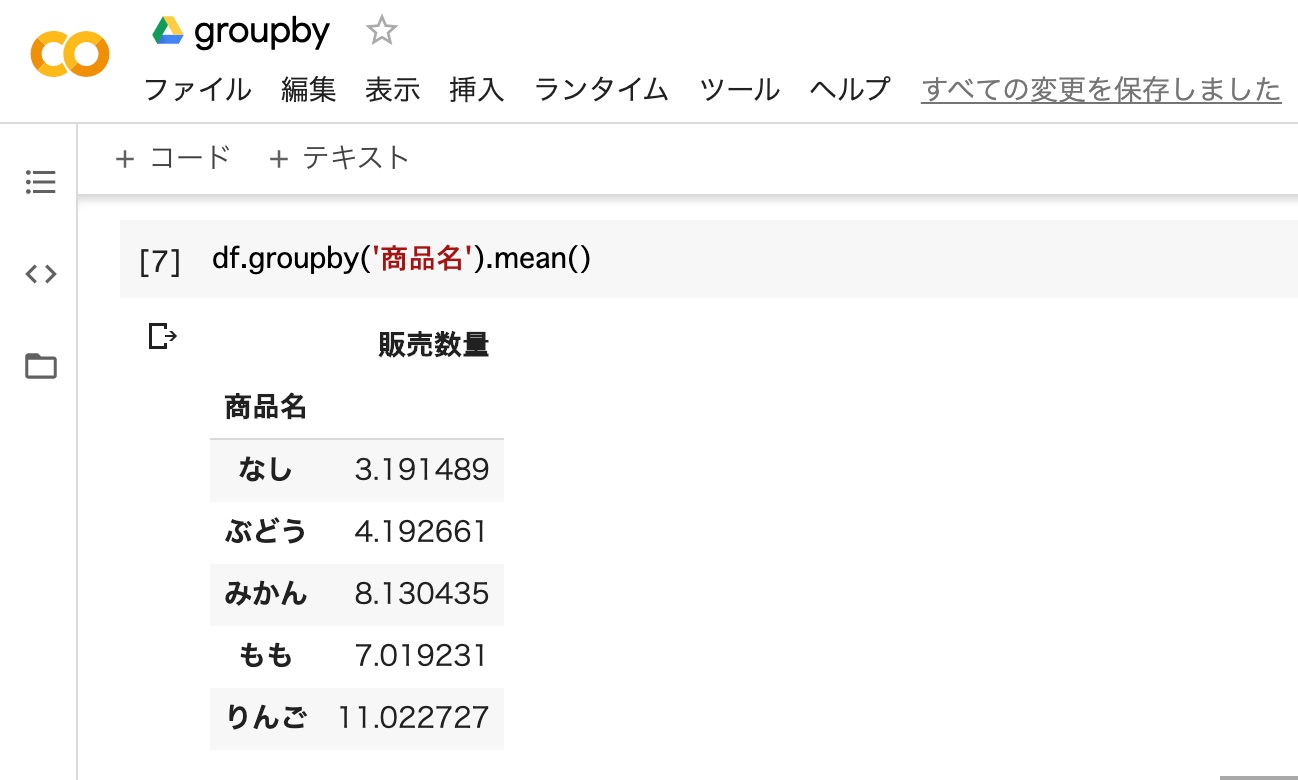
df.groupby('商品名').mean()
- 商品名の平均を算出
Pandas groupbyで統計量を算出(describe)
「groupby」と「describe」を組み合わせると、主要な統計量(count・mean・std・min・25%・50%・75%・max)を一括して算出します。
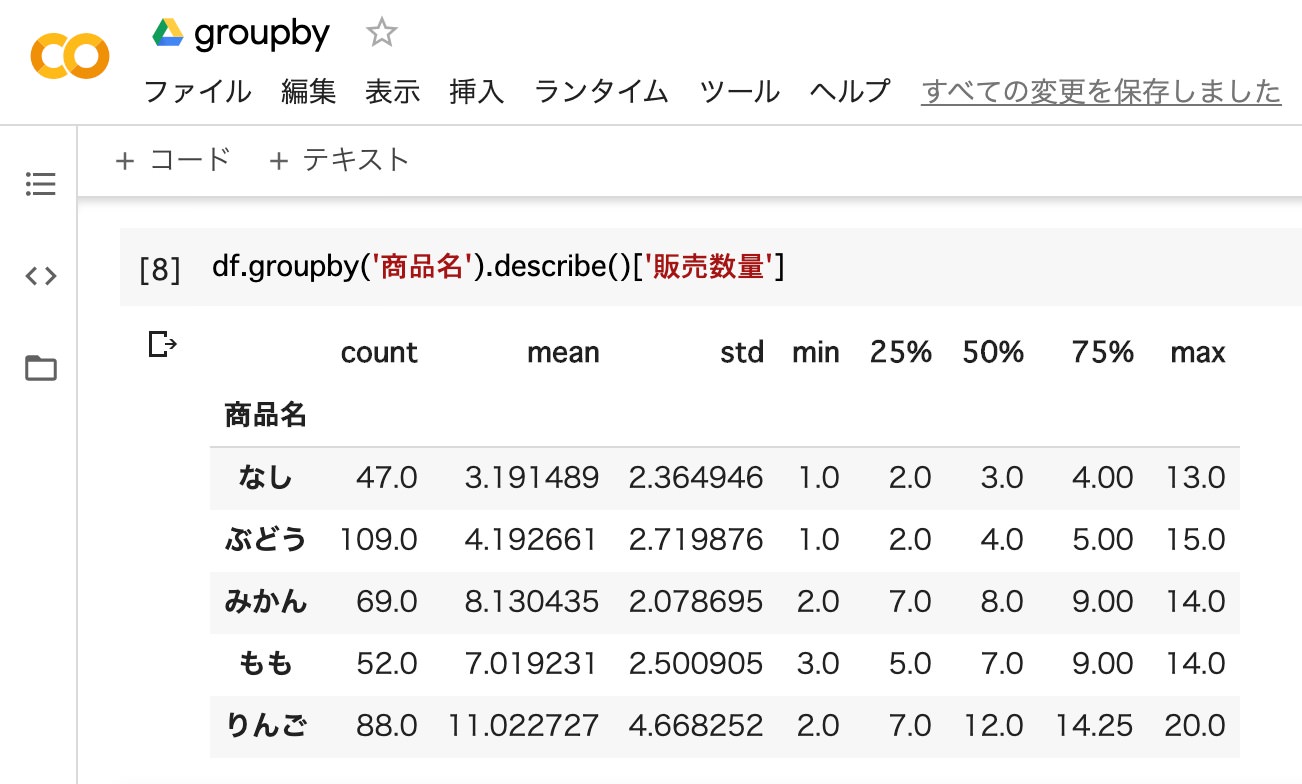
df.groupby('商品名').describe()['販売数量']
- ”商品名ごと”で”販売数量”の基本統計量を算出
Pandasのgroupbyの使い方まとめ
Pandasの「groupby」は、データ内容を把握する上でとても重要なテクニックです。DataFrameのバラバラのデータを「グループ化」し、任意の関数を実行することでデータ内容を効率的に把握することができます。
特に「groupby」は以下の関数・メソッドと組み合わせて使うことが多いです。
[st-mybox title=”” fontawesome=”” color=”#757575″ bordercolor=”#7ca1b7″ bgcolor=”#ffffff” borderwidth=”2″ borderradius=”2″ titleweight=”bold” fontsize=”” myclass=”st-mybox-class” margin=”25px 0 25px 0″]
- count
- sum
- describe
[/st-mybox]
ぜひ「groupby」の使い方をマスターして、データ分析にチャレンジしてください。最後まで読んでいただき、ありがとうございます。
