

データフレームで重複しているデータを削除(ユニークな値だけを抽出)する方法を説明します。
データフレームの確認(変更前)
職員リスト(staff_df)を元にデータを操作していきます。職員番号・名前・所属の全てが重複している場合と、所属だけが重複している場合があるので、それぞれの削除方法を説明します。
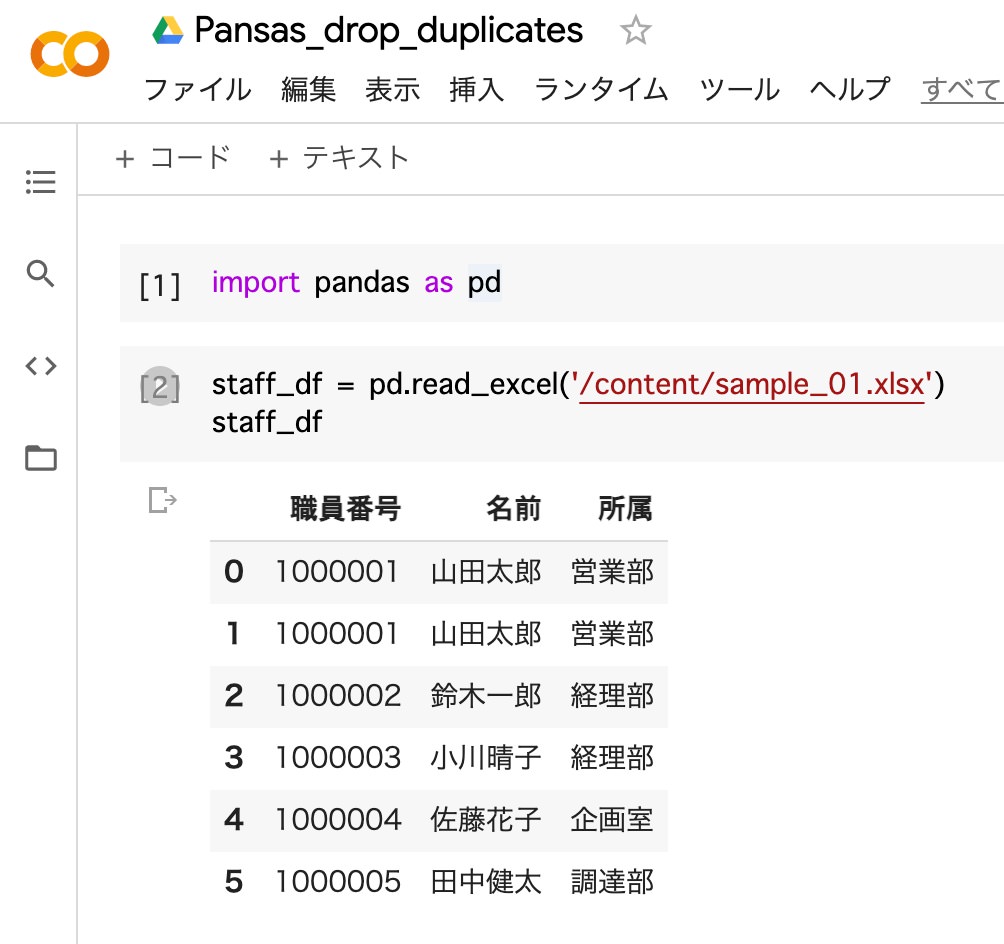
import pandas as pdstaff_df = pd.read_excel('/content/sample_01.xlsx') staff_df
1.pandasのインポート
2.データフレーム (staff_df)へExcelファイルの読み込み
3.データフレーム (staff_df)を表示
重複しているデータを削除する方法(全ての列)
drop_duplicatesメソッドで、職員番号・名前・所属の全てが重複しているデータを削除。
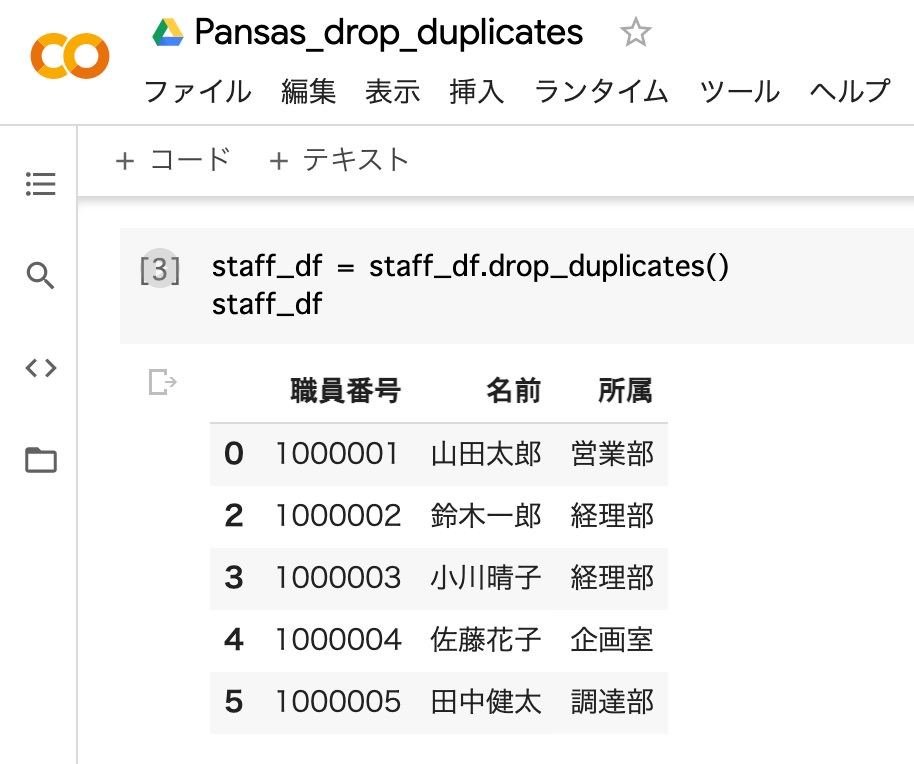
staff_df = staff_df.drop_duplicates()
staff_df1.変数(staff_df)に、重複しているデータ(山田太郎)を削除したデータを代入
2.データフレーム (staff_df)を表示
重複しているデータを削除する方法(指定した列)
drop_duplicatesメソッドの引数に列名(所属)を指定して、重複しているデータを削除。削除されるのは重複した後ろのデータ(小川晴子)。
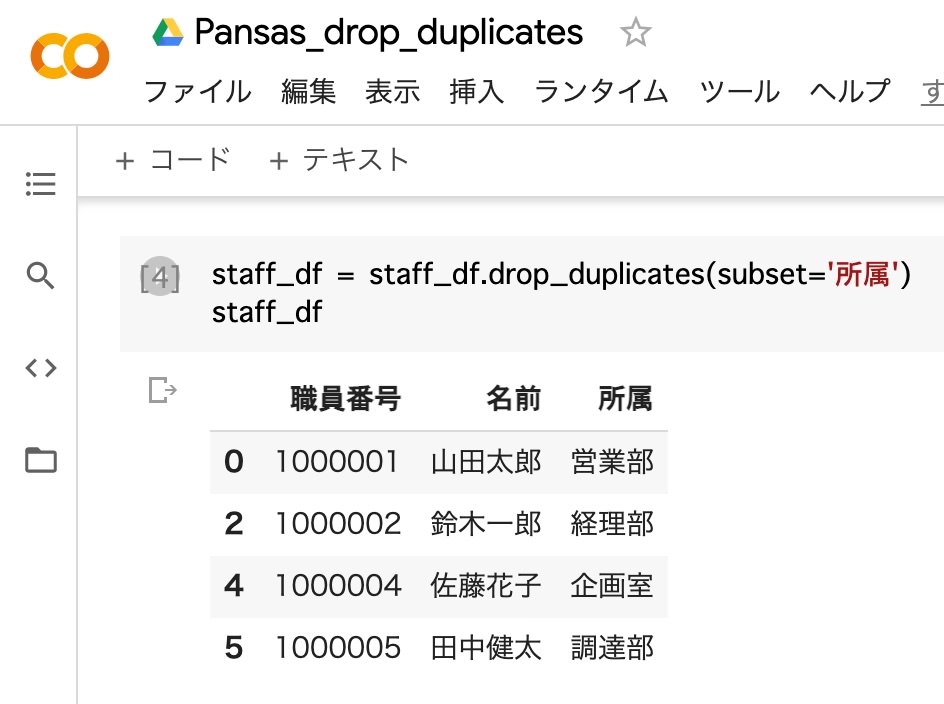
staff_df = staff_df.drop_duplicates(subset='所属')
staff_df1.変数(staff_df)に、重複しているデータ(所属)を削除したデータを代入
2.データフレーム (staff_df)を表示
