

scikit-learn 使い方(機械学習)多クラス分類
scikit-learnライブラリを使った、ロジスティック回帰分析による多クラス分類の方法を紹介します。
以前、紹介したロジスティック回帰分析では、2値(○ or ×)を予測しましたが、3値(○ or △ or ×)や4値(○ or △ or □ ×)など、多数のクラスに分類(予測)しなければならないケースも想定されるので、今回はその方法を解説します。
- scikit-learnの基本についてはこちら → Python scikit-learnを使った機械学習の実例(過去のデータから将来を予測)
アヤメの品種分類(3品種)
今回は、アヤメのデータから「セトサ種」「バージニカ種」「バージカラー種」の3品種に分類する予測モデルを作っていきます。

アヤメのデータの基本情報
scikit-learnでは、機械学習のための様々なdatasetが提供されており、アヤメのデータもその1つです。
アヤメの「がく片の長さ」「がく片の幅」「花びらの長さ」「花びらの幅」の150個のデータを使って、3品種に分類する予測モデルを作成します。
日本語表記に必要なモジュールをインストール
pip install japanize-matplotlib1.「pip install japanize-matplotlib」と入力して実行します。
機械学習に必要なモジュールのインポート
機械学習に必要なツールをインポートして、使用できるようにします。

import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns sns.set(font="IPAexGothic")
import sklearn from sklearn.linear_model
import LogisticRegression from sklearn.model_selection
import train_test_split from sklearn
import linear_model from sklearn.datasets
import load_iris1.「import pandas as pd」・・・データフレームを操作
2.「from pandas import Series,DataFrame」・・・1次元・2次元配列の処理
3.「import matplotlib.pyplot as plt」・・・グラフ作成(matplotlib)
4.「import japanize_matplotlib」・・・日本語対応(matplotlib)
5.「import seaborn as sns」・・・グラフ作成(seaborn)
6.「sns.set(font=”IPAexGothic”)」・・・日本語対応(seaborn)
7.「import sklearn」・・・機械学習のインポート
8.「from sklearn.linear_model import LogisticRegression」・・・ロジスティック回帰分析のインポート
9.「from sklearn.model_selection import train_test_split」・・・「訓練用」と「テスト用」にデータを分割
10.「from sklearn import linear_model」・・・回帰モデルのインポート
11.「from sklearn.datasets import load_iris」・・・アヤメデータのインポート
機械学習の事前準備_1(datasetからデータフレームへの変換)

ayame = load_iris()
X = ayame.data
Y = ayame.target
df1 = DataFrame(X,columns=['Sepal Length','Sepal Width','Petal Length','Petal Width'])
df2 = DataFrame(Y,columns=['Species'])
df1.columns = ['がく片の長さ', 'がく片の幅', '花びらの長さ','花びらの幅']
df2.columns = ['アヤメの種類']1.「ayame」にアヤメのデータを代入
2.Xに説明変数(’Sepal Length’,’Sepal Width’,’Petal Length’,’Petal Width’)を代入
3.Yに目的変数(’Species’)を代入
4.Xをデータフレーム の形式に変更
5.Yをデータフレーム の形式に変更
6.説明変数 Xの列名を日本語(がく片の長さ・がく片の幅・花びらの長さ・花びらの幅)に変更
7.目的変数 Yの列名を日本語(アヤメの種類)に変更
機械学習の事前準備_2(目的変数のデータ整理)
目的変数(アヤメの種類)の列に入力されているデータが数値(1・2・3)であるため、分かりやすくするために品種名(セトサ種・バージニカ種・バージカラー種)に変更します。

def iris(num):
if num == 0:
return 'セトサ種'
elif num == 1:
return'バージニカ種'
else:
return'バージカラー種'
df2['アヤメの種類'] = df2['アヤメの種類'].apply(iris)
df3 = pd.concat([df1,df2],axis=1)1.if文を使って、データが「1」のときは「セトサ種」、データが「2」のときは「バージニカ種」、それ以外(3)のときは「バージカラー種」と入力
2.説明変数(df1)と目的変数(df2)を結合して、1つのデータフレーム (df3)を作成
- if文の使い方についてはコチラ → Python if文の使い方(else,and,or,notなど)
アヤメのデータフレーム の内容確認
head()で最初の5行、tail()で最後の5行を確認。150個(0〜149)のデータがあるのが分かります。「アヤメの種類」が目的変数で、それ以外が説明変数です。
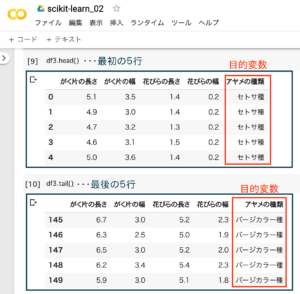
df3.head()
df3.tail()1.データフレーム の最初の5行を確認
2.データフレーム の最後の5行を確認
アヤメ3品種のそれぞれの特徴(パターン)を見える化
seabornを使ってアヤメの統計データをグラフ化します。各列同士の散布図を表示し、特徴量を比較。セトサ種(青色)は他の2品種に対して、特徴がはっきりしていることが分かります。
- seabornについてはこちら → Seaborn使い方(棒グラフなど)効果的・効率的なデータ分析の手法

sns.pairplot(iris,hue='アヤメの種類',size=2)1.ペアプロット図(散布図行列)の表示。各散布図の対角線にはヒストグラムが表示されます。
ロジスティック回帰(多クラス分類)の実行
アヤメの全てのデータは使わずに「訓練用」と「テスト用」にデータを分割し、機械学習を実行します。訓練用のデータで作成した予測モデルを、テスト用のデータで試すことで予測の精度を検証することができます。
logreg = LogisticRegression()
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
logreg.fit(X_train, Y_train)1.インスタンスの作成(ロジスティック回帰の設計図の具現化)
2.説明変数のデータを訓練用データ(X_train)とテスト用データ(Y_train)に分割。目的変数のデータを、訓練用データ(X_test)とテスト用データ(Y_test)に分割
3.ロジスティック回帰分析の実行(予測モデルの作成)
ロジスティック回帰(多クラス分類)モデルの検証結果
「訓練用データ」で作成した機械学習モデルを、「テスト用データ」で精度を検証した結果、92%という高い精度を得ました。

まとめ
ロジスティック回帰分析(多クラス分類)を使い、予測結果を3値(セトサ種・バージニカ種・バージカラー種)に分類することができました。
ペアプロット図(各列同士の散布図)を見ると分かるように、3品種にそれぞれ特徴があったため、精度の高い予測モデル(92%)を作成することができました。
今回のアヤメのデータは150個でしたが、ビッグデータ(例 : 100万のデータ)を使って機械学習を行うことで、より精度の高い実用的な予測モデルを作成することが可能です。

