

目次 非表示
- scikit-learnとは
- 機械学習(Machine learning)とは
- 糖尿病患者のdatasetを使った機械学習の具体例
- 「糖尿病患者の疾患進行度」の学習モデル作成の前準備
- 「糖尿病患者」のデータ確認
- 「糖尿病患者の疾患進行度」の状況
- 「糖尿病患者の疾患進行度」とBMIとの相関関係
- 「糖尿病患者の疾患進行度」と「BMI」を使った単回帰モデルの可視化
- 「糖尿病患者の疾患進行度」の訓練データ・正解データの作成
- 「糖尿病患者の疾患進行度」の重回帰分析のモデル作成
- 「糖尿病患者の疾患進行度」の予測
- 「糖尿病患者データ」の正規化(実行)
- 「糖尿病患者データ」の正規化(確認)
- 「糖尿病患者の疾患進行度」の重回帰分析のモデル評価
- まとめ
scikit-learnとは

scikit-learn(サイキット・ラーン)とはpythonライブラリの1つで、オープンソースで公開されている機械学習(Machine learning)を行うためのツールです。
機械学習で使用する数式がパッケージとして実装されており、Pythonのコードを使って、分類・回帰・クラスタリングを行うことができます。
機械学習(Machine learning)とは
機械学習とは、コンピューターが大量のデータの中からある特徴(パターン)を見つけ出すことです。
そのパターンに従って新しいデータを当てはめることで、「データの分類」や「将来の予測」が可能です。
・機械学習の 4つのステップ
1.機械学習の元となるデータの準備
2.予測する対象(目的変数)と学習モデルの決定
3.学習モデルの訓練
4.学習モデルによる予測
学習モデルの種類について
scikit-learnの学習モデルにはいくつかの種類があり、予測したい内容に合わせて適切なモデルを選択する必要があります。
scikit-learnのアルゴリズムマップ
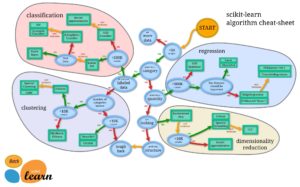
- classification(クラス分類)→ データの属するグループを予測する。
- clustering (クラスタ分類) → データ同士の類似度によって、データをグループ化する。
- regression(回帰分析) → 因果関係のある複数の変数のうち、一方の変数から値を予測する。
- dimensionality reduction(データの次元圧縮) → 多次元の情報を、その意味を保ったまま情報を圧縮する。
糖尿病患者のdatasetを使った機械学習の具体例

scikit-learnには機械学習やデータ分析をすぐに試せるように、いくつかのdatasetが一般公開されています。今回は糖尿病患者の442名分の年齢・性別・BMIなどのデータを元に、1年後の疾患進行状況を予測する学習モデル(重回帰分析)を作成します。
「糖尿病患者の疾患進行度」の学習モデル作成の前準備
1.糖尿病患者の、1年後の疾患進行度を予測するモデルを作成する
2.作成した予測モデルにサンプルデータを使って、将来を予測する
3.作成した予測モデルで、寄与率の高い係数を調べる
日本語表記に必要なモジュールをインストール
グラフを日本語表記に対応させます。

pip install japanize-matplotlib1.「pip install japanize-matplotlib」と入力して実行します。
データ分析に必要なモジュールのインポート
データ分析に必要なツールをインポートして、使用できるようにします。
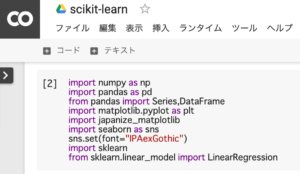
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import sklearn
from sklearn.linear_model import LinearRegression1.「import numpy as np」・・・数値計算を効率的に行う
2.「import pandas as pd」・・・データフレームを操作
3.「from pandas import Series,DataFrame」・・・1次元・2次元配列の処理
4.「import matplotlib as matplotlib」・・・グラフ作成(matplotlib)
5.「import japanize_matplotlib」・・・日本語対応(matplotlib)
6.「import seaborn as sns」・・・グラフ作成(seaborn)
7.「sns.set(font=”IPAexGothic”)」・・・日本語対応(seaborn)
8.「import sklearn」・・・機械学習
9.「from sklearn.linear_model import LinearRegression」・・・線形回帰モデル
インストールした「ライブラリ」「パッケージ」「モジュール」を使用するためには、最初にインポートする必要があります。
Excelファイルの読み込み
糖尿病患者のdataset(オリジナルデータ)は、こちらから取得することができます → 糖尿病患者dataset(オリジナルデータ)
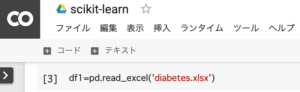
df1 = pd.read_excel('diabetes.xlsx')1.エクセルファイル(‘diabetes.xlsx’)の読み込み
糖尿病患者のデータは、修正(日本語化)を加えています
「糖尿病患者」のデータ確認
データの列名は「年齢」「性別」「BMI」「平均血圧」「総コレステロール」「悪玉コレステロール」「善玉コレステロール」「tch」「itg」「glu」「1年後の疾患進行度」の11種類です。

df.head()1.df.head()と入力し、データの内容確認
datasetの基本情報
データセットの基本情報を確認します。データの数は442個存在することが分かります。
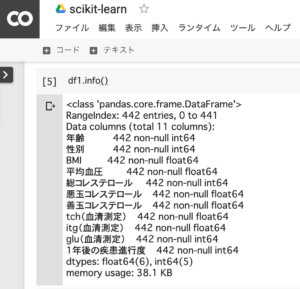
df.info()1.df.info()と入力し、データセットの基本情報を確認
「糖尿病患者の疾患進行度」の状況
442人の糖尿病の1年後の疾患進行度の状況を把握します。
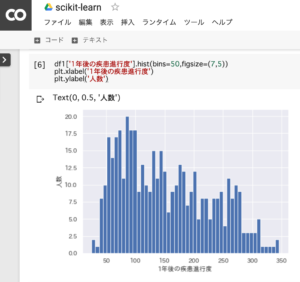
df1['1年後の疾患進行度'].hist(bins=50,figsize=(7,5))
plt.xlabel('1年後の疾患進行度')
plt.ylabel('人数')1.1年後の疾患進行度の人数割合をグラフ化
2.x軸のラベルに「1年後の疾患進行度」と表示
3.y軸のラベルに「人数」と表示
「糖尿病患者の疾患進行度」とBMIとの相関関係
1年後の疾患進行度とBMIの数値との間に、ゆるい相関関係があることが分かります。
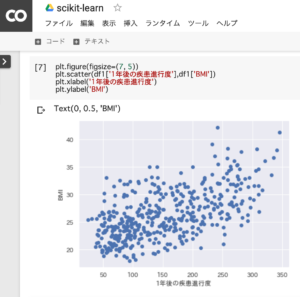
plt.figure(figsize=(7, 5))
plt.scatter(df1['1年後の疾患進行度'],df1['BMI'])
plt.xlabel('1年後の疾患進行度')
plt.ylabel('BMI')1.グラフの大きさを修正(横:7、縦:5)
2.plt(matplotlib)を使って、散布図を作成
3.x軸のラベルに「1年後の疾患進行度」と表示
4.y軸のラベルに「BMI」と表示
インスタンスの作成
インスタンス(データ処理の方法・メソッド)の作成。LinearRegressionと記入することで、線形回帰モデルを用いた数値の予測を行うことができます。

lreg = LinearRegression()1.lreg = LinearRegression()と入力
「糖尿病患者の疾患進行度」と「BMI」を使った単回帰モデルの可視化
重回帰分析の前に、2つの変数(1年後の疾患進行度・BMI)を使った単回帰分析を行います。この分布図に表示されている直線が相関関係(予測)を表しています。1年後の疾患進行度とBMIには、ゆるい相関関係があることが分かります。

sns.lmplot('1年後の疾患進行度','BMI',data = df2,height=5.5, aspect=1.2)1.sns(seaborn)を使って、「1年後の疾患進行度」と「BMI」との単回帰分析の結果を表示
「糖尿病患者の疾患進行度」の訓練データ・正解データの作成
糖尿病患者のデータから、訓練データ(年齢・性別・BMIなど)と正解データ(1年後の疾患進行度)を作成します。
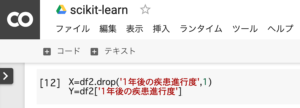
X=df2.drop('1年後の疾患進行度',1)
Y=df2['1年後の疾患進行度']1.訓練データ(X)の作成・・・「1年後の疾患進行度」以外のデータ
2.正解データ(Y)の作成・・・「1年後の疾患進行度」のデータ
「糖尿病患者の疾患進行度」の重回帰分析のモデル作成
訓練データ(X)と正解データ(Y)を使って、予測値を返すモデル(重回帰分析モデル)を作成します。

lreg.fit(X,Y)1.lreg.fit(X,Y)と記入し、重回帰分析のモデルを作成。
この1行で訓練データ(年齢・性別・BMI・平均血圧・総コレステロール・悪玉コレステロール・善玉コレステロール・tch・itg・glu)と、正解データ(1年後の疾患進行度)との関係を分析し、予測値を返すモデルを作成することができます。
「糖尿病患者の疾患進行度」の予測
重回帰分析のモデルが作成できたので、糖尿病患者のサンプルデータ(テスト①〜③)を使って、1年後の疾患進行度の予測を行います。予測値は実行結果として表示されています。

test1 = np.array([[24,1,25,84,198,131,40,5,5,89]])
lreg.predict(test1)
test1 = np.array([[50,2,30,100,180,120,50,4,5,77]])
lreg.predict(test1)
test1 = np.array([[35,1,25,80,130,50,60,4,4,60]])
lreg.predict(test1)1.サンプルデータ(テスト①)の入力
2.テスト①の予測実行
3.サンプルデータ(テスト②)の入力
4.テスト②の予測実行
5.サンプルデータ(テスト③)の入力
6.テスト③の予測実行
「糖尿病患者データ」の正規化(実行)
糖尿病患者のデータを正規化(元データを平均0、標準偏差が1のものに変換)し、重回帰分析による各項目(年齢・性別・BMI等)の係数を比較し、順位付けできるようにします。
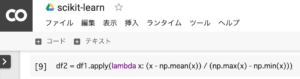
df2 = df1.apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))1.lambda関数を使って正規化
「糖尿病患者データ」の正規化(確認)
各項目(年齢・性別・BMI等)が正規化されていることが分かります。
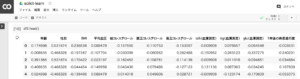
df.head()1.データフレームの内容の確認
「糖尿病患者の疾患進行度」の重回帰分析のモデル評価
各項目の係数(訓練データの回答データへの寄与率)を見ると、「総コレステロール(0.692708)」が最も高いことが分かりました。
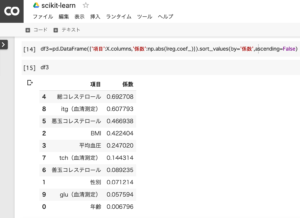
df3 = pd.DataFrame({'項目':X.columns,'係数':np.abs(lreg.coef_)}).sort_values(by='係数',ascending=False)
df31.データフレーム (df3)に重回帰分析の結果(係数)を代入します。
2.データフレーム (df3)を表示します。
まとめ
単回帰分析では説明変数は1種類(BMI)だけでしたが、重回帰分析では「総コレステロール」「itg」「悪玉コレステロール」など10種類の説明変数を同時に扱うことができるため、より精度の高い予測モデルを作成できます。
また、機械学習には「教師あり学習」と「教師なし学習」の2つのモデルがあります。
「教師あり学習」とは、学習データ(説明変数)に回答データ(目的変数)を紐づけて学習させる方法です(今回の糖尿病患者のデータ)。
一方「教師なし学習」とは、コンピュータ自身が類似したデータ同士を分類(クラスタリング)したり、頻出パターンを見つけ出す学習方法です。
有名な例として「おむつとビールが一緒に買われる場合が多い」といった、人間には思いもよらない発見をすることがあります。

