

scikit-learn 使い方(機械学習)未来の予測
scikit-learnライブラリを使った、ロジスティック回帰分析による予測方法を紹介します。ロジスティック回帰分析とは、いくつかの要因から2値(○ or ×)を予測することができる統計的回帰モデルの1つです。
今回はeラーニングシステムの過去の学習状況(100人分のサンプルデータ)から、ある対象者が全ての学習を完了するか・完了しないかを予測するモデルを作っていきます。
- scikit-learnの基本についてはこちら → Python scikit-learnを使った機械学習の実例(過去のデータから将来を予測)
日本語表記に必要なモジュールをインストール
pip install japanize-matplotlib1.「pip install japanize-matplotlib」と入力して実行します。
機械学習に必要なモジュールのインポート
機械学習に必要なツールをインポートして、使用できるようにします。
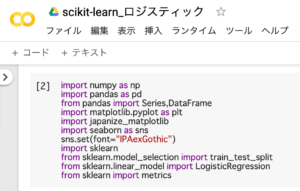
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import sklearn
from sklearn.model_selection
import train_test_split
from sklearn.linear_model
import LogisticRegression
from sklearn import metrics1.「import numpy as np」・・・数値計算を効率的に行う
2.「import pandas as pd」・・・データフレームを操作
3.「from pandas import Series,DataFrame」・・・1次元・2次元配列の処理
4.「import matplotlib as matplotlib」・・・グラフ作成(matplotlib)
5.「import japanize_matplotlib」・・・日本語対応(matplotlib)
6.「import seaborn as sns」・・・グラフ作成(seaborn)
7.「sns.set(font=”IPAexGothic”)」・・・日本語対応(seaborn)
8.「import sklearn」・・・機械学習
9.「from sklearn.model_selection import train_test_split」・・・機械学習モデルの評価①
10.「from sklearn.linear_model import LogisticRegression」・・・ロジスティック回帰分析
11.「from sklearn import metrics」・・・機械学習モデルの評価②
Excelファイルの読み込み
Excel(※学習状況)の読み込み 。※サンプルデータです。
df1 = pd.read_excel('学習状況.xlsx')1.Excelファイル(‘学習状況.xlsx’)の読み込み
過去の学習状況のデータ確認
データの列名は「年齢」「平均点数」「回答時間」「トライ回数」「受講率」「受講フラグ」の6種類です。目的変数が「受講フラグ(0=受講未了、1=受講完了)」で、それ以外のデータが説明変数となります。
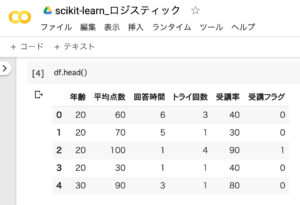
df.head()1.df.head()と入力し、データの内容確認
「年齢別の学習状況」のグラフ化
年齢別の学習状況(受講未了・受講完了)をグラフ化した結果、20代と50才以上の「受講未了」割合(青色)が高かったことが分かります。
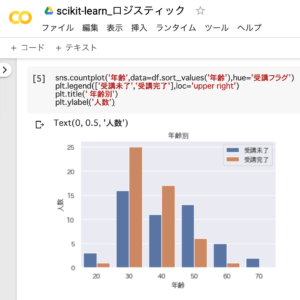
sns.countplot('年齢',data=df.sort_values('年齢'),hue='受講フラグ')
plt.legend(['受講未了','受講完了'],loc='upper right')
plt.title(' 年齢別')
plt.ylabel('人数')1.「受講未了」と「受講完了」の人数を年齢別にグラフ化
2.凡例の位置を右上に表示
3.グラフのタイトルを「年齢別」に指定
4.y軸のラベルに「人数」と表示
「平均点数別の学習状況」のグラフ化
平均点数別の学習状況(受講未了・受講完了)をグラフ化した結果、60点以下は「受講未了」だったことが分かります。
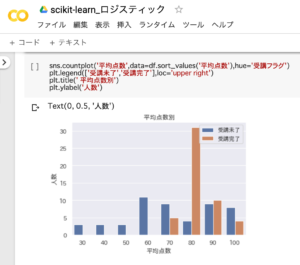
sns.countplot('平均点数',data=df.sort_values('平均点数'),hue='受講フラグ')
plt.legend(['受講未了','受講完了'],loc='upper right')
plt.title(' 平均点数別')
plt.ylabel('人数')1.「受講未了」と「受講完了」の人数を平均点数別にグラフ化
2.凡例の位置を右上に表示
3.グラフのタイトルを「平均点数別」に指定
4.y軸のラベルに「人数」と表示
「トライ回数別の学習状況」のグラフ化
トライ回数別の学習状況(受講未了・受講完了)をグラフ化した結果、5回以上は全員「受講未了」だったことが分かります。
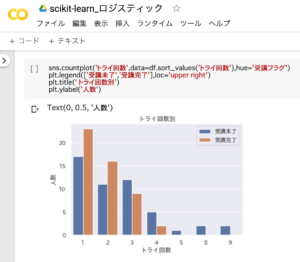
sns.countplot('トライ回数',data=df.sort_values('トライ回数'),hue='受講フラグ')
plt.legend(['受講未了','受講完了'],loc='upper right')
plt.title(' トライ回数別')
plt.ylabel('人数')1.「受講未了」と「受講完了」の人数をトライ回数別にグラフ化
2.凡例の位置を右上に表示
3.グラフのタイトルを「トライ回数別」に指定
4.y軸のラベルに「人数」と表示
学習状況の「訓練データ」「正解データ」の作成
学習状況データから、訓練データ(年齢・平均点数・回答時間・トライ回数・受講率)と正解データ(受講フラグ)を作成します。
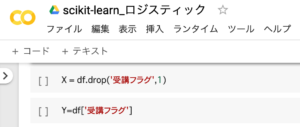
X = df.drop('受講フラグ',1)
Y = df['受講フラグ']1.訓練データ(X)の作成・・・「受講フラグ」以外のデータ
2.正解データ(Y)の作成・・・「受講フラグ」のデータ
ロジスティック回帰分析の「モデル作成」と「モデル精度の評価」
訓練データ(X)と正解データ(Y)を使って、予測値を返すモデル(ロジスティック回帰分析モデル)を作成します。
モデル精度を評価した結果、87%と高い精度を得ました。
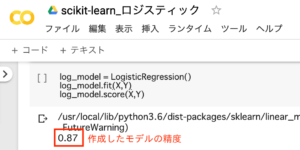
log_model = LogisticRegression()
log_model.fit(X,Y)
log_model.score(X,Y)1.LogisticRegression()と記入し、インスタンスの作成
2.log_model.fit(X,Y)と記入し、ロジスティック回帰分析のモデルを作成
3.log_model.score(X,Y)と記入し、モデル精度を評価
作成した機械学習モデルの検証方法
学習状況の全てのデータを使って予測モデルを作成した結果、87%という高い精度を得ることができましたが、次にこのモデルの精度を改めて検証していきます。全てのデータを使わずに「モデル作成用」と「テスト用」にデータを分割することで、モデル精度を検証することが可能です。
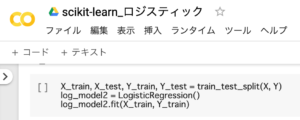
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
log_model2 = LogisticRegression()
log_model2.fit(X_train, Y_train)1.説明変数のデータを訓練用データ(X_train)とテスト用データ(Y_train)に分割。目的変数のデータを、訓練用データ(X_test)とテスト用データ(Y_test)に分割。
2.インスタンスの作成
3.ロジスティック回帰分析のモデルを作成
作成した機械学習モデルの検証結果
モデル精度を検証した結果、全てのデータを使用した時とほぼ同じ、88%と高い精度を得ました。学習状況の全てのデータを使わず訓練用データとテスト用データに分割することで、過学習を防いだ適切なモデルを作成できるというメリットがあります。過学習とは、訓練用データに適合し過ぎた予測モデルのことです。訓練用データに適合し過ぎて(過学習して)しまい、実際のデータに当てはめた際に精度が落ちることがあるため、それを防いでくれます。
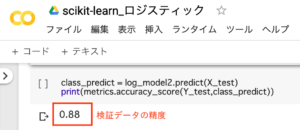
class_predict = log_model2.predict(X_test)
print(metrics.accuracy_score(Y_test,class_predict))1.log_model2.predict(X_test)と記入し、検証モデルの精度を評価
2.検証モデルの精度の結果を表示
「学習結果」の予測
ロジスティック回帰分析のモデルが作成できたので、受講者のサンプルデータ(①〜③)を使って、未来の受講結果の予測を行います。予測値は実行結果(0=受講未了、1=受講完了)として表示されています。
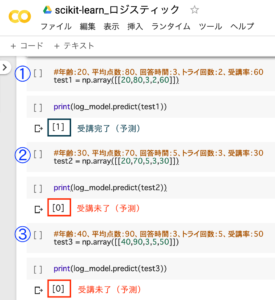
test1 = np.array([[20,80,3,2,60]])
print(log_model.predict(test1))
test2 = np.array([[20,70,5,3,30]])
print(log_model.predict(test2))
test3 = np.array([[40,90,3,5,50]])
print(log_model.predict(test3))1.サンプルデータ(テスト①)の入力
2.テスト①の予測実行
3.サンプルデータ(テスト②)の入力
4.テスト②の予測実行
5.サンプルデータ(テスト③)の入力
6.テスト③の予測実行
まとめ
ロジスティック回帰分析を使うと予測結果を「0」 or 「1」で判定してくれるため、二者択一の結果を予測するのに適しています。重回帰分析と同様、複数の説明変数と1つの目的変数を設定しコンピュータにその関係性を学習させることで、人には気づけなかった特徴(パターン)を見つけ出すことができます。
今回はeラーニングシステムの学習状況から「予測モデル」を作成し、「受講未了」となる可能性が高い対象者を抽出することができました。対象者には事前に注意喚起行う等、効率的な受講管理に役立てることも可能です。

