


- データ解析ってどういうもの?
- Pythonによるデータ解析の方法を知りたい
- データ解析の具体的な手順を教えてほしいPythonによるデータ解析入門

データ解析とは、大量のデータの中から「意味のある情報」を発掘する手法のことです。具体的には以下のようなことを検討します。
- 一定の法則がないか
- 異常値がないか
- 因果関係・相関関係がないか
例えば、アイスクリームは夏によく売れますが、冬にはあまり売れません。
このように、ある商品の”売上データ”などから、気温との相関関係を客観的に調査する際にPythonは活躍します。
Pythonを使うと統計データ(平均・標準偏差・最大値など)の表示・グラフ化を簡単に実行できるので、最高のツールだと思います。
Pythonによるデータ解析入門|グラフ作成ライブラリSeabornとは?

SeabornとはPython標準ライブラリの1つで、統計データを簡単にグラフ化するツールの1つです。
Pythonを使ったでグラフ作成といえばMatplotlibが有名ですが、さらにハイレベルなグラフを作成できます。
Seabornサンプル図はこちら → http://seaborn.pydata.org/examples/index.html
Pythonによるデータ解析入門|タイタニック号の生存者の調査
今回はデータ解析の具体例として、映画にもなったタイタニック号沈没事故で、どのような人が生存できたのかを調査していきます。
タイタニック号沈没事故

1912年4月14日、イギリス・サウサンプトンからアメリカ合衆国・ニューヨーク行きの処女航海中の4日目に北大西洋で起きた沈没事故。
当時世界最大の客船であったタイタニックは、1912年4月14日の23時40分に氷山に衝突し、乗客2,224人の内1,514人が亡くなりました。
kaggleについて
![]()
このタイタニック号の沈没事故に使用するデータは、kaggle(カグル)という機械学習モデルのコンペを行うプラットフォームからダウンロードしています。
kaggleのコンペでは、予測モデルの精度を競い合い、上位者には数万から数十万ドルといった高額な優勝賞金が出ることでも有名です。
今回のデータ解析の目的
説明するにあたって、データ解析の目的を設定した方が分かりやすいので、今回はデータ下記の「問い」を解明していくことにします。
タイタニック号沈没事故のデータ解析の目的
- タイタニック号には、どのような人が乗っていたのか?
- タイタニック号の、それぞれの客室クラスの人数割合はどれくらいか?
- タイタニック号沈没事故の生存者に、どのような傾向があったか?
日本語表記に必要なモジュールをインストール
まずはグラフの日本語に対応するためのモジュールをインストールします。
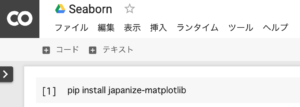
pip install japanize-matplotlib1.「pip install japanize-matplotlib」と入力して実行。グラフ化した時のタイトル・ラベルが日本語で表示されます。
pipi(ピッピ)について
「pip」とは、Pythonで使用するライブラリ・パッケージをインストールするシステムのことです。「ライブラリ」「パッケージ」「モジュール」の違いをそれぞれ把握しておいてください。
- ライブラリ → 本棚のようなもの
- パッケージ → 本のようなもの
- モジュール → 本のページのようなもの
データ解析に必要なライブラリ等のインポート
インポート(import)は、パッケージやモジュールを呼び出して使用するために必要となります。
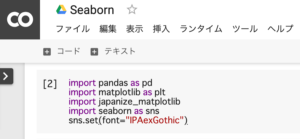
import pandas as pd
import matplotlib as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")1.「import pandas as pd」・・・データ分析(pandas)
2.「import matplotlib as matplotlib」・・・グラフ作成(matplotlib)
3.「import japanize_matplotlib」・・・日本語対応(matplotlib)
4.「import seaborn as sns」・・・グラフ作成(seaborn)
5.「sns.set(font=”IPAexGothic”)」・・・日本語対応(seaborn)
インストールした「ライブラリ」「パッケージ」「モジュール」を使用するためには、最初にインポートする必要があります。
Excelファイルの読み込み
kaggleからダウンロードした、タイタニック号沈没事故のデータを読み込みます。こちらからもダウンロードできます。
- Google Colabによる環境構築についてはGoogle Colab(グーグルコラボ)環境構築をご覧ください。
- Excelファイルの読み込み方法については Pythonを使ったExcelの操作 をご覧ください。
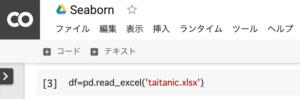
df=pd.read_excel('taitanic.xlsx')1.エクセルファイル(‘taitanic.xlsx’)をDataFrame形式に変換
読み込んだファイル(データ)の確認
データの列名は「名前」「年齢」「性別」「客室」「生存フラグ」の5種類が確認できます。「生存フラグ」の0は死亡、1は生存を表しています。
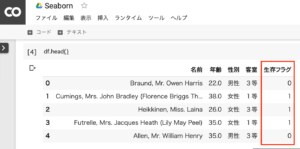
df.head()1.DataFrame(‘taitanic.xlsx’)の内容の確認
データの基本情報
次にデータ全体の基本情報を確認します。「年齢」以外のデータは891個存在することが分かります。「年齢」は714個しかありません。
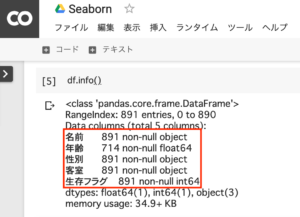
df.info()1.DataFrame(‘taitanic.xlsx’)の基本情報の確認
タイタニック号の乗客の男女の割合
PythonライブラリのSeabornを使うと、たった1行のコードを実行するだけで簡単にグラフを作成することができます。女性客よりも男性客が多かったことが分かります。
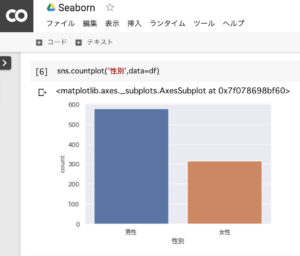
sns.countplot('性別',data=df)1.sns(seaborn)を使って、男女の人数をグラフ化
タイタニック号の客室毎の人数割合
タイタニック号は、3等客室の人数割合が高かったことがわかります。
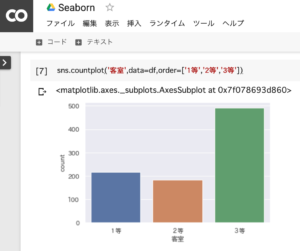
sns.countplot('客室',data=df,order=['1等','2等','3等'])1.sns(seaborn)を使って、客室別の人数をグラフ化
タイタニック号の客室毎の人数割合(男女別)
タイタニック号の3等客室には、男性の割合が高かったことが分かります。
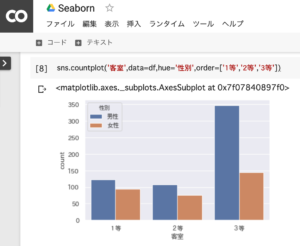
sns.countplot('客室',data=df,hue='性別',order=['1等','2等','3等'])1.sns(seaborn)を使って、客室別の人数(男女別)をグラフ化
タイタニック号の乗客の年齢分布
タイタニック号には、20代〜30代の比較的若い人が乗っていたことが分かります。
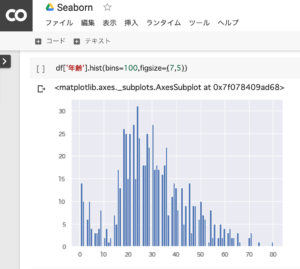
df['年齢'].hist(bins=100,figsize=(7,5))1.年齢別の分布状況をグラフ化。hist関数により、データフレーム からmatplotlibを使ってグラフ化してくれます。
タイタニック号の乗客の年齢分布(男女別)
Pythonを使うと、このようなハイレベルなグラフ(カーネル密度推定)も簡単に作成できます。
- カーネル密度推定:標本データから全体の分布を推定する手法です。タイタニック号の乗船客の年齢別の分布状況から、全体の分布を推定して滑らかなヒストグラムを作成できます。
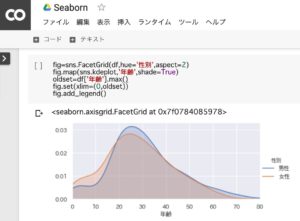
fig=sns.FacetGrid(df,hue='性別',aspect=2)
fig.map(sns.kdeplot,'年齢',shade=True)
oldset=df['年齢'].max()
fig.set(xlim=(0,oldset))
fig.add_legend()1.sns(seaborn)を使って、性別で層別化
2.1のデータをkdeplot(カーネル密度推定)を使って、年齢別に全体の分布を推定
3.x軸(年齢)の幅を最大値に設定
4.x軸(年齢)の範囲を0から最大値に設定
5.凡例(男性・女性)を追加
タイタニック号の乗客の年齢分布(客室毎)
タイタニック号の客室毎の乗客の年齢分布を見ると、3等客室には若い人の割合が高かったことが分かります。
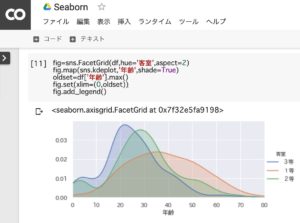
fig=sns.FacetGrid(df,hue='客室',aspect=2)
fig.map(sns.kdeplot,'年齢',shade=True)
oldset=df['年齢'].max()
fig.set(xlim=(0,oldset))
fig.add_legend()1.sns(seaborn)を使って、客室で層別化
2.1のデータをkdeplot(カーネル密度推定)を使って、年齢別に全体の分布を推定
3.x軸(年齢)の幅を最大値に設定
4.x軸(年齢)の範囲を0から最大値に設定
5.凡例(1等・2等・3等)を追加
タイタニック号の乗客の生存者の傾向(客室毎)
それではタイタニック号の生存者の傾向を見てみます。この沈没事故では、1等客室→2等客室→3等客室の順に生存者の割合が高いことが分かりました。
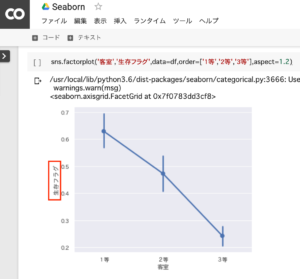
sns.factorplot('客室','生存フラグ',data=df,order=['1等','2等','3等'],aspect=1.2)1.sns(seaborn)を使って、客室別(1等・2等・3等)の生存率をグラフ化。折れ線グラフに付いているバーは誤差の範囲を示しています。
タイタニック号の乗客の生存者の傾向(客室別・男女別)
さらに生存者の割合を男女別に見てみると、女性の生存者の割合が高いことが分かりました。これは、男性よりも女性を優先して救助されたためだと考えられます。特に、2等客室の男性は1等客室に比べて大きく下がっているのに対し、2号客室の女性はあまり下がっていないことが分かります。
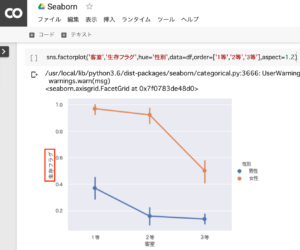
sns.factorplot('客室','生存フラグ',hue='性別',data=df,order=['1等','2等','3等'],aspect=1.2)1.客室別(1等・2等・3等)の生存者を状況を男女別にグラフ化。
タイタニック号の乗客の生存者の傾向(年齢別・客室別・男女別)
さらに生存者の割合を「年齢別」に細分化してみます、すると年齢が若い人ほど生存者の割合が高いことが分かります。沈没に際し、船長が「女性と子ども優先(ウィメン・アンド・チルドレン・ファースト、Women and children first)」と命じたことで、優先して救助されたと考えられます。
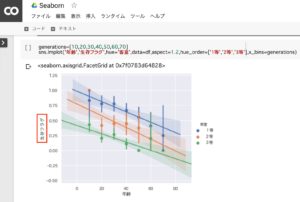
generations = [10,20,30,40,50,60,70]
sns.lmplot('年齢','生存フラグ',hue='客室',data=df,aspect=1.2,hue_order=['1等','2等','3等'],x_bins=generations)1.年齢別・客室別の生存者を状況をグラフ化
Pythonによるデータ解析入門|まとめ
このように、Pythonでは少ないコードでデータを可視化(グラフ化)できるのが特徴です。
Excelでグラフを作成しようとすると、何かと手作業が発生してしまいます。
Pythonを使えば、大量のデータを効率的に解析できるので、ぜひ試してみてください。

